최근 장애 하나의 조사 단위
APM 이후의 장애 조사 작업대
봐야 할 게 너무 많은 장애 대응, 이제 감으로 찾지 마세요.
최근 연관된 모든 장애들을 하나의 Incident 로 묶고 Log, Trace, Metric 에 기반한 Service Map, Incident 데이터, RCA 초안까지 어디서 부터 봐야 할지 보여줍니다.
PrometheusGrafanaOpenTelemetryClickHouseKubernetesAI/API Gateway
연결 패널 · severity
trace · log · event
Service Map · slow edge
담당자 · 조치 기록
사실 · 근거 · 후속 작업
WORKFLOW
Alert부터 RCA 초안까지, 팀이 따라갈 순서가 보입니다.
상태를 본 뒤 팀은 Incident, Evidence, Telemetry, Dependency, War Room, RCA 초안 순서로 움직입니다. Monithub는 기존 APM과 대시보드 신호를 이 조사 흐름에 맞춰 모아, 원인 후보와 확인 근거, 조치 기록을 같은 화면 안에 남깁니다.
Incident
알림과 이상 신호를 최근 장애 하나의 조사 단위로 묶습니다.
Evidence
영향 대상, 심각도, 연결 패널, activity를 한 Incident에서 비교합니다.
Telemetry
Trace, log, Kubernetes event를 Incident 시간창에 맞춰 봅니다.
Dependency
Service Map에서 upstream/downstream 관계와 느린 edge를 골라봅니다.
War Room
담당자, action, 확인 결과를 대화와 함께 기록합니다.
RCA 초안
확인한 사실, 의심 원인, 근거 링크, 조치, 후속 작업을 사람이 검토할 초안으로 정리합니다.
근거 모으기
늦게 합류해도 같은 근거에서 시작합니다.
열린 Incident, 연결된 패널, War Room 진입점을 한곳에 두면 담당자가 바뀌어도 무엇을 봤고 다음에 어디로 갈지 다시 설명하지 않아도 됩니다.
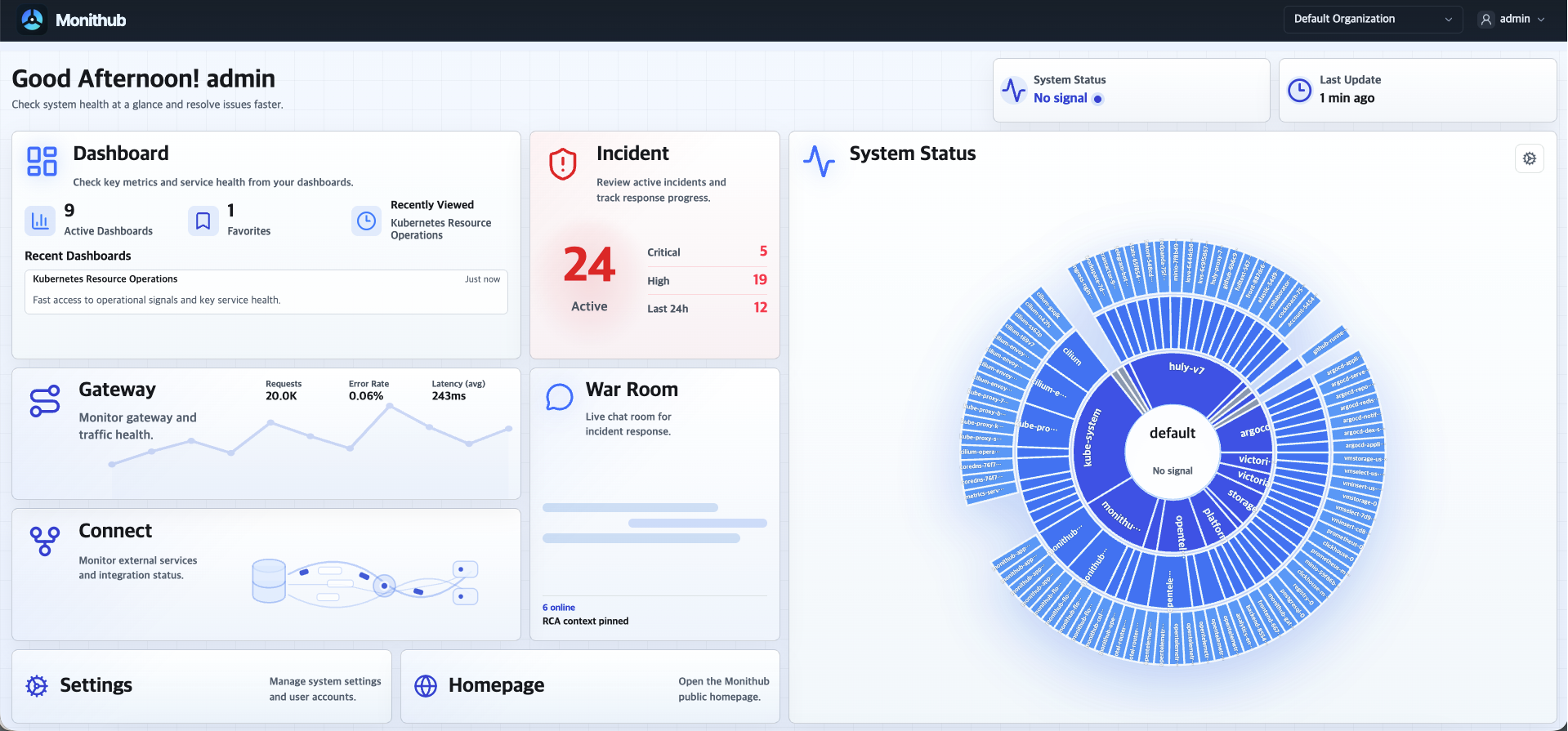
Trace 근거
Telemetry 시간창을 맞춰 의심 구간을 검토합니다.
Incident에서 파생된 시간창으로 trace와 요청 단위 지연을 열어 봅니다. 느린 span, 오류 구간, attribute가 RCA 초안에 남길 근거 링크가 됩니다.
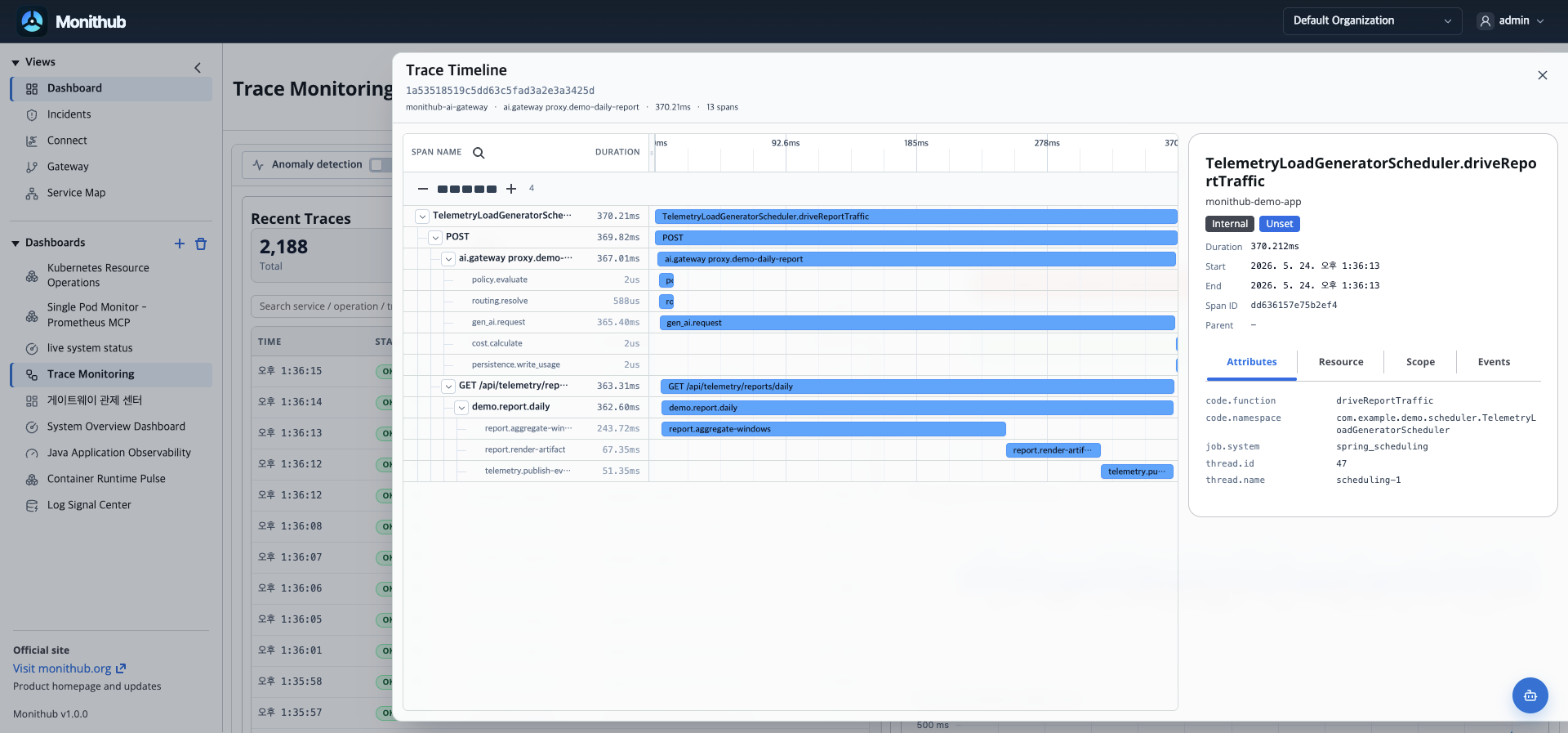
Dependency 영향
Dependency로 영향 범위와 다음 담당자를 좁힙니다.
Service Map은 장애 target에서 upstream/downstream 관계를 확인하게 합니다. 느린 edge와 실패 구간을 보고 어느 서비스와 담당자에게 다음 확인을 맡길지 정합니다.
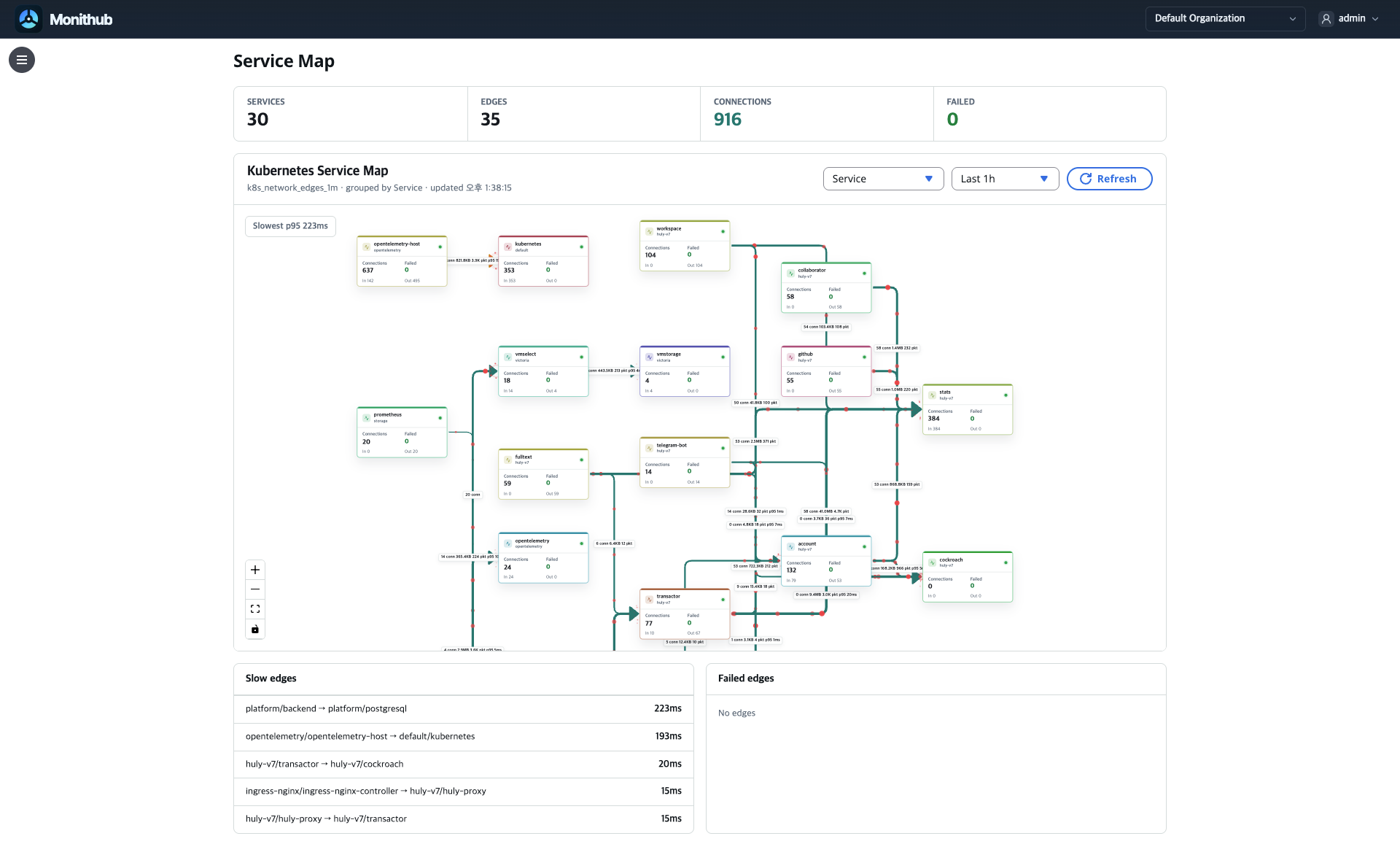
조치 조율
War Room은 확인 순서와 조치를 잃어버리지 않습니다.
담당자, action, 확인 결과, linked incident가 같은 맥락에 남습니다. 대시보드 링크만 공유해 끊기던 대응 흐름을 팀 기록으로 이어갑니다.

RCA 초안
장애가 끝난 뒤, RCA를 처음부터 다시 쓰지 마세요.
AI/API latency, usage, provider metadata 같은 보조 신호까지 Incident 근거에 붙여 둡니다. 회고할 때는 기억을 더듬지 않고, 확인한 사실과 의심 원인, 근거 링크, 조치, 후속 작업을 한 번에 검토합니다.
PRICING / WAITLIST
최근 장애 하나만 가져오면, 도입 범위가 보입니다.
먼저 Incident 타임라인과 근거 링크가 실제 대응에 도움이 되는지 확인합니다. 그 다음 War Room 운영, 데이터 경계, 전용 배포까지 팀 상황에 맞게 넓힙니다.
무료 기술 검증
₩0 · 대표 장애 1개 검증
최근 장애 하나를 가져와 Incident 타임라인, 근거 링크, RCA 초안까지 남는지 살펴봅니다.
최근 장애 시나리오 1개RCA 초안과 후속 작업 확인
Team
사용량 기반 · 팀 운영 플랜
실제 대응 팀이 같은 근거로 움직이고 반복 장애 기록을 팀 운영 기준으로 삼습니다.
War Room summary와 action 기록복수 cluster, host, service
Enterprise
맞춤 계약 · 전용 기술 검증
데이터 경계, private deployment, 보안 정책, 감사 요구가 있는 조직은 실제 배포 조건과 운영 책임 범위를 함께 확인합니다.
고객 VPC / 온프렘 검토 메모전용 운영 지원 범위 협의
WAITLIST
Monithub 정식 출시 알림을 받아보세요.
정식 출시 전에는 대기 명단을 먼저 받습니다. 출시 소식과 대표 장애 시나리오 기반 제품 흐름을 이메일로 보내드립니다. 별도 문의는 하단 이메일 주소로 보내주세요.